LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯
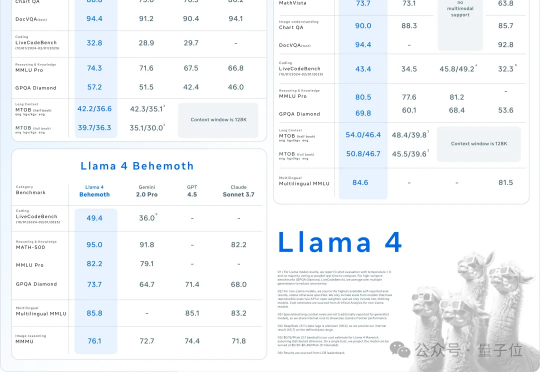
LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯AI不过周末,硅谷也是如此。大周日的,Llama家族上新,一群LIama 4就这么突然发布了。这是Meta首个基于MoE架构模型系列,目前共有三个款:Llama 4 Scout、Llama 4 Maverick、Llama 4 Behemoth。
来自主题: AI资讯
11238 点击 2025-04-06 12:15